










Продолжаем публиковать адаптированный перевод исчерпывающего обзора «Трансформации в геотехнике с помощью искусственного интеллекта: достижения, проблемы и перспективы», который был подготовлен международной группой исследователей. Подробная аннотация к этой работе приведена в начале первой части. Сегодня представляем вторую часть. В ней рассматриваются основные проблемы использования искусственного интеллекта в геотехнике, которые существуют на сегодняшний день. Отметим, что нумерация рисунков здесь продолжает начатую в первой части. В список литературы вошли статьи, на которые были ссылки в первых двух частях.

На рисунке 6 показаны ключевые проблемы, препятствующие широкому внедрению искусственного интеллекта в геотехнику. Общее для них связано с тем, как методы использования ИИ в геотехнике вписываются в более широкий контекст инженерного освоения подземного пространства. Несмотря на то что существуют возможности для обмена данными и моделями с целью получения более целостного представления о подземной среде, для создания стандартизированной системы такого обмена требуются общие формализованные способы представления и структурирования знаний (онтологии) и совместимость данных. Далее эти проблемы и возможные пути их решения рассматриваются подробнее.
Рис. 6. Основные проблемы применения искусственного интеллекта в геотехнике и их возможные решения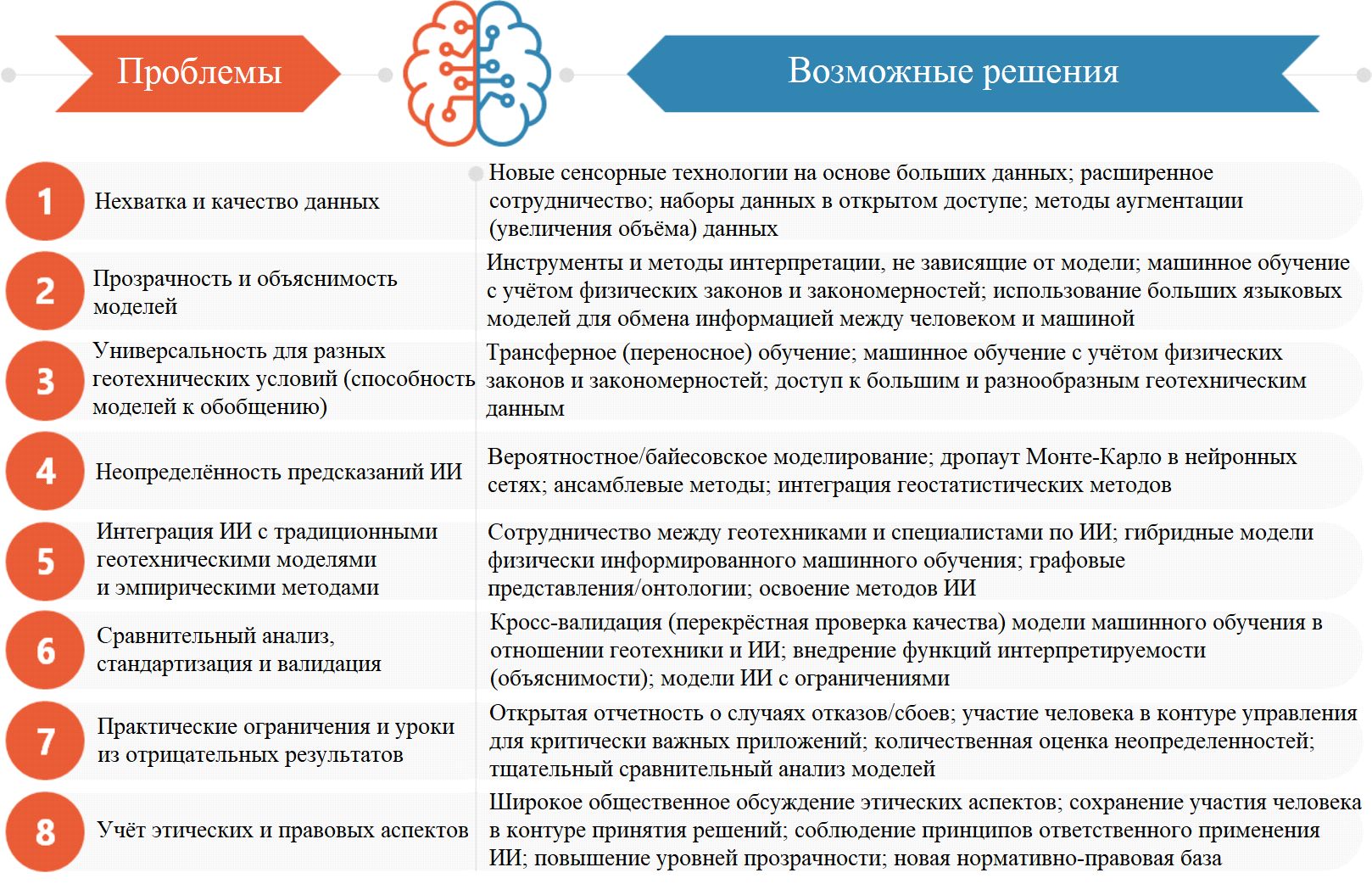
Проблема 1: нехватка и качество данных
Все процессы, основанные на данных, зависят от размера и качества обучающей выборки. Поэтому одним из существенных препятствий для широкого применения ИИ в геотехнике является нехватка высококачественных, аннотированных и разнообразных данных. Наборы геотехнической информации требуют тщательного аннотирования, в ходе которого специалисты в соответствующей области присваивают данным «метки» с точными и подробными сведениями о свойствах грунтов, геологических особенностях и геотехнических параметрах, а также комментариями по процедурам испытаний.
Достоверно установлено, что ограниченная доступность данных оказывает существенное влияние на машинное обучение [156], повышая риск неточностей, слабой способности к обобщению и, в крайних случаях, ложных прогнозов, возникающих из-за переобучения.
Имеется настоятельная необходимость в установлении единых стандартов оценки качества геотехнических данных с учетом различий в надежности испытаний, связанных с человеческим фактором, методами тестирования или используемыми приборами.
Недавно были предложены структурированные подходы к оценке качества данных при геотехническом мониторинге [157 и др.] – и стандарты обмена данными, такие как AGS и DIGGS, снова актуальны. В условиях недостатка данных разработчики моделей часто прибегают к вероятностным суррогатным моделям [9], к использованию аугментации (увеличения объема) данных с учетом специфики предметной области или к трансферному обучению (при котором модель, обученная для одной задачи, повторно используется для решения другой, связанной с первой).
Перспективное направление для решения рассматриваемой проблемы – объединение обученных моделей разных заинтересованных сторон, которое позволит преодолеть трудности, связанные с обменом данными в геотехническом сообществе. Обычно такой подход предполагает обучение общей модели на разных децентрализованных наборах данных, хранящихся у разных участников. При этом каждый владелец данных обучает модель локально, а обмен осуществляется только обновлениями модели (но не исходными данными). Для координации обучения на разных площадках используется единый набор параметров и гиперпараметров. Данная стратегия также соответствует принципам операционных процессов машинного обучения (Machine Learning Operations, MLOps), которые обеспечивают отслеживаемое, воспроизводимое и масштабируемое управление моделями.
Проблему нехватки данных помогут смягчить и современные методы их сбора, например передовые сенсорные технологии (такие как распределенные волоконно-оптические датчики [158], беспроводные ячеистые сети [157]) и дистанционное зондирование (например, спутниковая интерферометрическая радиолокация с синтезированной апертурой (InSAR) [159]).
Также можно повысить доступность разнообразной информации путем совместных усилий по обмену анонимизированными наборами данных и по установлению стандартизированных форматов данных. Примером может послужить база данных испытаний свай на нагрузку DINGO [160].
Кроме того, для расширения существующих наборов данных могут применяться методы науки о данных, такие как аугментация данных, трансферное обучение и генерация синтетических данных. Это позволит моделям ИИ лучше обобщать информацию и эффективно работать при различных геотехнических сценариях, несмотря на изначальный недостаток данных.
Проблема 2. Прозрачность и объяснимость моделей
Алгоритмы искусственного интеллекта (в частности, глубокого обучения) часто воспринимаются как «черные ящики», которые практически не позволяют понять лежащие в их основе процессы принятия решений. В геотехнике, где прозрачность и понимание прогнозов моделей имеют решающее значение для обоснованного принятия решений, отсутствие объяснимости является серьезным препятствием.
Для решения этой проблемы требуются новые методы, позволяющие извлекать осмысленные сведения из сложных моделей ИИ. Например, для обучения модели на стандартах по геотехническому проектированию с целью проверки соответствия проектных решений нормативным требованиям может использоваться обработка естественного языка.
К дополнительным методам можно отнести: универсальные инструменты интерпретации, не зависящие от модели; анализ чувствительности; механизмы внимания, которые позволяют анализировать результаты работы модели и, как следствие, выявлять наиболее значимые факторы, влияющие на геотехнические прогнозы.
Перспективным направлением также является машинное обучение с учетом физических законов (физически информированное), которое позволяет интегрировать в модели ИИ знания по предметной области, что дает возможность использовать относительные преимущества моделей, основанных на физических законах, и методов, основанных на данных, для повышения как интерпретируемости, так и надежности прогнозов [161].
Недавние успехи в создании физически информированных конститутивных моделей [162 и др.] также показывают, что к более достоверным прогнозам может приводить основанное на данных моделирование с ограничениями, обусловленными законами физики (физически ограниченное). Кроме того, может использоваться метод стохастического отключения узлов/нейронов сети (метод дропаута), причем не только в качестве регуляризатора во время обучения, но и для генерации стохастических выборок на этапе вывода с применением дропаута по методу Монте-Карло, иногда называемого просто дропаутом Монте-Карло. Среднее значение предсказаний и их дисперсия, соответственно, отражают наилучшую оценку и эпистемическую (вызванную неполнотой знаний) неопределенность выходных данных модели (рис. 7, 8).
Рис. 7. Схема моделирования, принятая в работе Чжана и др. [163]: а – архитектура, показывающая входные параметры модели, а также взаимодействие между выходными параметрами нейронной сети и ограничениями, обусловленными законами физики (обведено красным) при использовании в данном примере инкрементального нелинейного моделирования; б – пример отключения части связей нейронной сети при дропауте по методу Монте-Карло (отключенные связи показаны красным)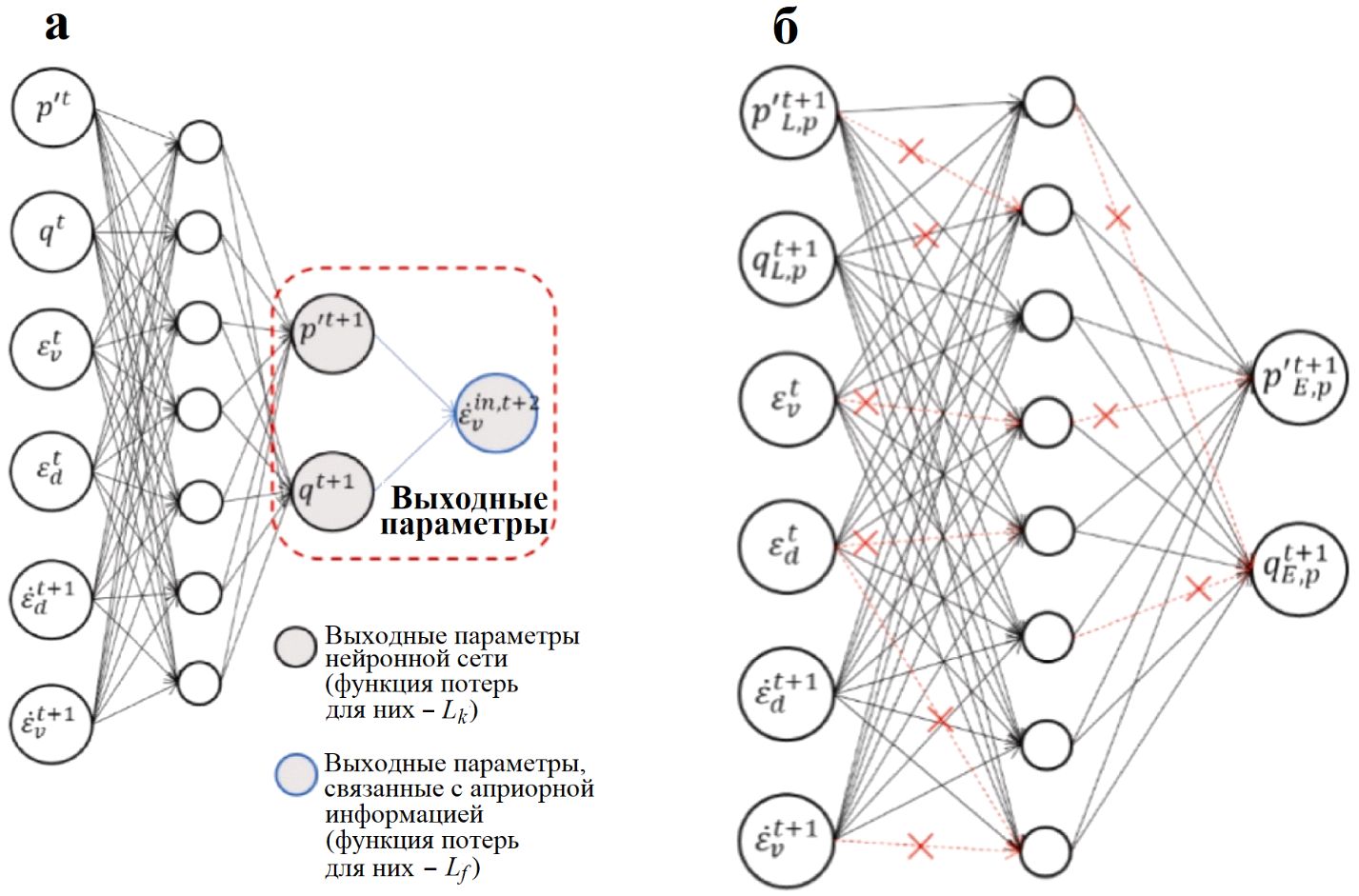
Рис. 9. Схема применения метода трансферного обучения для определения границ между слоями грунтов (по [28]). Буквенное обозначение: fT(·) – функция дообучения модели на целевых данных (точка по центру строки в скобках используется вместо ее аргумента, который здесь не конкретизирован) 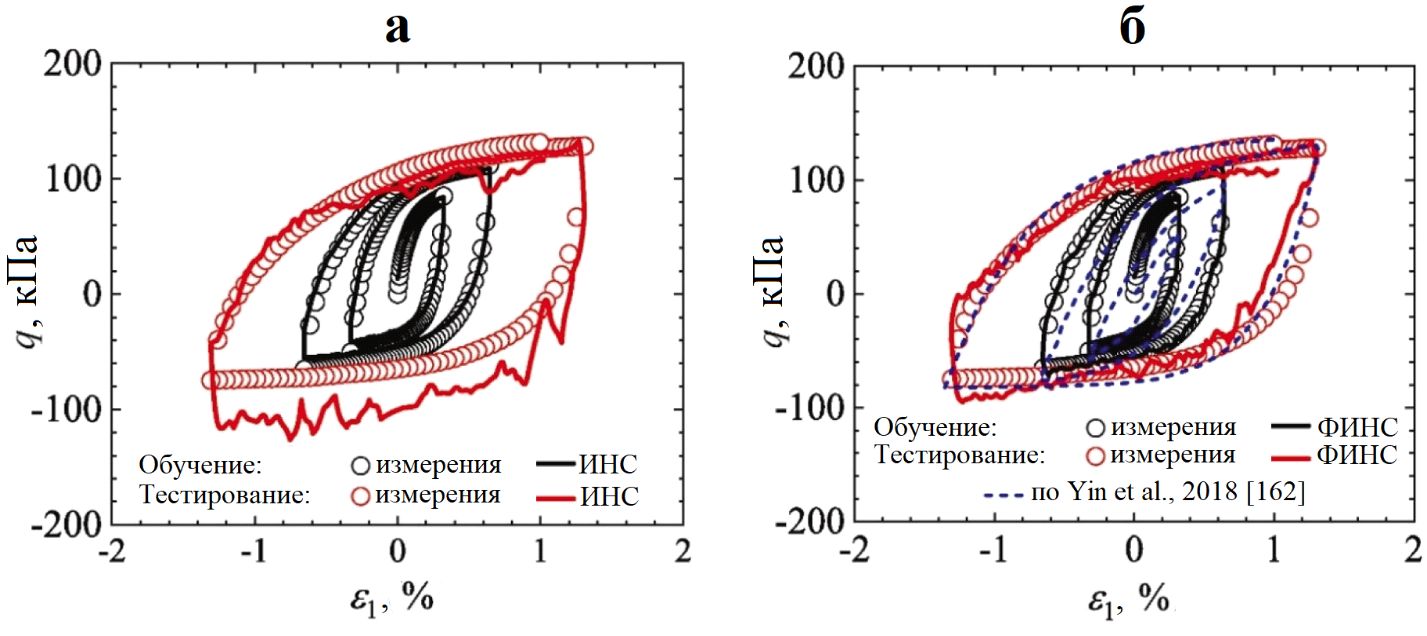
Кроме того, благодаря машинному обучению с учетом физических законов (физически информированному) модели могут учитывать фундаментальные геотехнические механизмы, что обеспечивает надежную экстраполяцию на разные условия [163 и др.].
Решающее значение для повышения способности моделей к обобщению имеет также обеспечение как репрезентативности обучающих наборов данных, так и достаточного их разнообразия.
Преодоление рассматриваемой проблемы позволит создавать более универсальные и надежные модели ИИ, пригодные для широкого применения на практике в целях решения реальных геотехнических задач.
Проблема 4. Неопределенность предсказаний искусственного интеллекта
Оценки неопределенности в геотехнике особенно необходимы из-за высокой цены, которую приходится платить за ошибки. Однако получение таких оценок с помощью моделей искусственного интеллекта остается сложным.
Надежные и научно обоснованные средства учета неопределенности можно получить с помощью вероятностного моделирования, основанного на байесовских методах машинного обучения. В частности, показано, что с моделированием геотехнической неопределенности на фундаментальном уровне можно хорошо справиться с использованием регрессии на основе гауссовского процесса [6, 9 и др.] (рис. 10). Даже для детерминированных моделей ИИ существуют методы оценки эпистемической (обусловленной недостатком знаний) неопределенности. Например, для нейронных сетей одним из наиболее распространенных методов проверки чувствительности выходных данных модели к ее конкретной архитектуре является дропаут по методу Монте-Карло. Имеются и такие популярные подходы, как ансамблевые методы, например бутстрэппинг (выборка с возвращением).
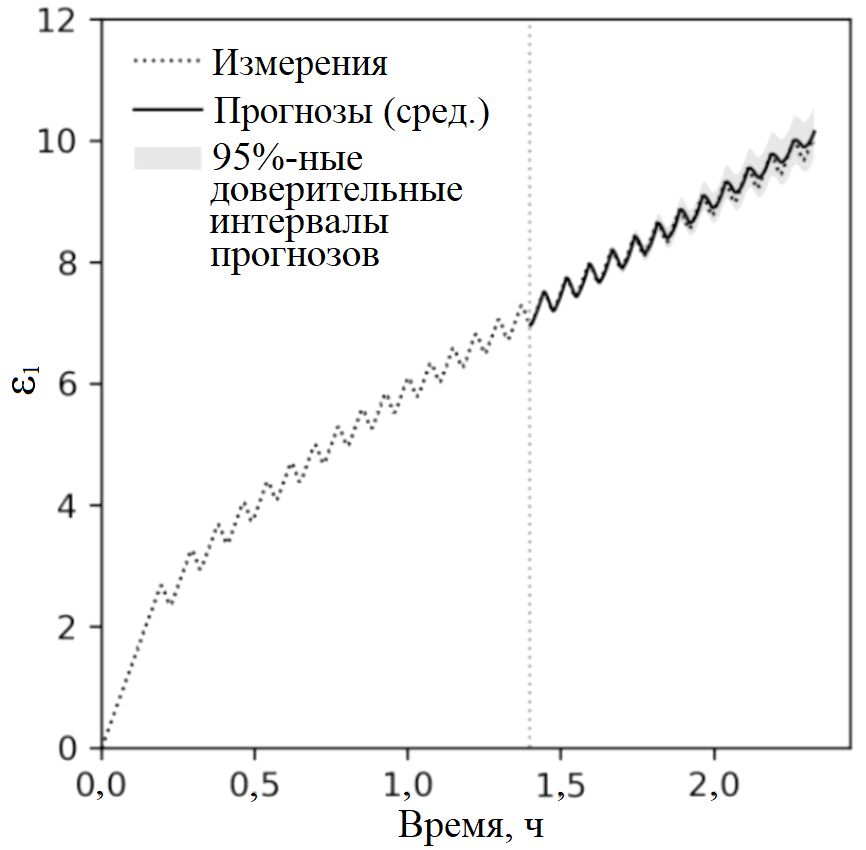
Рис. 10. Сопоставление относительных осевых деформаций (ε1), измеренных при циклическом трехосном сжатии в недренированных условиях и спрогнозированных с помощью модели регрессии на основе гауссовского процесса с ковариационной функцией LE+SE*PER, где SE, LE и PER – экспоненциальная квадратичная, линейная и периодическая компоненты ковариационной функции соответственно [9]
Разработка систем, в которых геостатистические методы интегрированы с моделями искусственного интеллекта, также позволит получить более полное представление о пространственных неопределенностях. Признание наличия и учет неопределенности грунтовых условий в прогнозах ИИ не только повысят доверие к таким геотехническим моделям, но и предоставят геотехникам и лицам, принимающим решения, ценную информацию для обоснованного выбора.
Проблема 5. Интеграция искусственного интеллекта с традиционными геотехническими моделями и эмпирическими методами
Несмотря на то что искусственный интеллект способен анализировать большие многомерные наборы геотехнических данных, для обеспечения точности и содержательности интерпретаций решающую роль играет включение профессиональных знаний и понимания контекста.
Не менее значимой задачей является обеспечение соответствия моделей ИИ общепризнанным в геотехнике принципам, нормативно-правовым документам и теориям. Одним из перспективных направлений решения этой задачи может стать автоматизированная проверка соответствия проектных геотехнических решений, основанных на данных, требованиям нормативных документов [168 и др.].
Также необходим междисциплинарный подход, предполагающий сотрудничество между специалистами в сферах искусственного интеллекта и геотехники.
Сильные стороны методов, основанных на данных и базирующихся на знании физических законов, могут сочетаться в гибридных моделях, дающих более интерпретируемые (объяснимые) и заслуживающие доверия результаты. Кроме того, можно явно задавать и объединять профессиональные знания в моделях ИИ с помощью графов знаний и онтологий.
В долгосрочной перспективе эффективное решение рассматриваемой проблемы, вероятно, потребует повышения квалификации современных геотехников, чтобы они могли анализировать не только данные, но и модели, основанные на этих данных. Крайне важно, чтобы решения на основе искусственного интеллекта вырабатывались в русле профессионального мышления и необходимых геотехнических знаний.
Проблема 6. Сравнительный анализ, стандартизация и валидация
Вероятность возникновения переобучения и, как следствие, выдачи ложных прогнозов для алгоритмов искусственного интеллекта существенно выше, чем для традиционных проектных моделей, что объясняется их сильно нелинейными составляющими. В отличие от традиционных численных моделей, результаты работы которых проверяются с помощью упрощенных аналитических моделей в целях подтверждения их обоснованности, для алгоритмов ИИ может не быть подобного механизма валидации.
Валидация моделей ИИ в геотехнике обычно проводится с использованием k-кратной перекрестной проверки (по k подвыборкам) или с помощью тестирования на отложенной выборке, не участвовавшей в обучении. При этом для оценки способности к обобщению применяются такие показатели эффективности, как среднеквадратическое отклонение, коэффициент детерминации R2, средняя абсолютная ошибка, а также, все чаще, границы неопределенности (интервал возможной ошибки модели). Однако специфические для предметной области проблемы (например, автокорреляция геопространственных данных для участка изысканий) требуют особенно тщательной разработки методики валидации.
Внедрение искусственного интеллекта в геотехнику требует баланса между точностью, временем обучения и вычислительными ресурсами, которые также сильно зависят от настройки гиперпараметров. Основные параметры (например, скорость обучения, глубина архитектуры, параметры, отвечающие за регуляризацию) требуют систематической настройки, часто с использованием поиска по сетке гиперпараметров (перебора их фиксированных комбинаций) или с помощью байесовского поиска (с применением байесовской вероятностной модели).
Простые модели (например, на основе деревьев решений или линейные) быстро обучаются даже на стандартных ноутбуках, тогда как модели глубокого обучения (например, для 3D данных или задач, интегрирующих в модель физические законы) могут требовать часов или дней работы даже с помощью высокопроизводительных графических процессоров (GPU). Процесс вывода прогнозов обычно проходит быстро, однако обучение может быть дорогостоящим для небольших организаций, если не использовать предварительно обученные модели или облачные сервисы.
Существующие геотехнические модели (например, модифицированная модель «Кэм-клэй» – Cam Clay) являются по своей сути детерминированными, давая согласованные результаты независимо от конкретных данных, использованных для обучения. Геотехники могут опираться на устоявшиеся принципы и математические формулы, лежащие в основе этих моделей, чтобы с высокой степенью уверенности прогнозировать поведение геотехнических материалов. Такая предсказуемость позволяет практикам понимать сильные и слабые стороны, а также области применения конкретной комплексной геомеханической (конститутивной) модели, что делает возможной ее эффективную валидацию путем сравнения ее прогнозов с экспериментальными или полевыми данными. Устойчивость и согласованность, присущие конститутивным моделям, являются ключевыми факторами их непреходящей ценности в геотехнике.
Напротив, модели ИИ, будучи основанными на данных и зависящими от разнообразных наборов данных, использованных при обучении, могут демонстрировать вариативность результатов, что затрудняет создание универсально надежной системы предсказаний.
Для решения этой проблемы необходимо создать основу для перекрестной проверки между выходными данными моделей ИИ и результатами использования традиционных геотехнических методов. Такой подход может включать применение искусственного интеллекта в качестве дополнительного инструмента, а не отдельного решения, что позволит постоянно сравнивать результаты с устоявшимися геотехническими знаниями.
Дополнительно поспособствовать выявлению потенциальных расхождений и повысить доверие к результатам работы искусственного интеллекта в контексте геотехнической практики может интеграция в модели ИИ возможностей интерпретируемости, например алгоритмов, обеспечивающих объяснимость.
Еще одним эффективным решением являются ограничения моделей ИИ, обусловленные известными и общепринятыми теоретическими или эмпирическими концепциями.
Проблема 7. Практические ограничения и уроки из отрицательных результатов
В опубликованных работах по применению искусственного интеллекта в геотехнике результаты исследований редко относят к неуспешным, однако в публикациях более широкого спектра фиксируются повторяющиеся типы неудач, которые явно следует признать. К ним относятся:
Тенденция к публикации только положительных итогов затрудняет формирование полного и точного представления об эффективности работы моделей, что говорит о важности открытых и прозрачных сообщений о негативных результатах.
Таким образом, целесообразно выделить области, для которых на сегодняшний день могут быть предпочтительнее традиционные подходы:
1) принятие проектных решений, регулируемых нормативно-правовыми документами и/или аналитическими методами с использованием надежно подтвержденных запасов прочности;
2) проекты на основе крайне ограниченных или гетерогенных данных, когда проведение строгой валидации модели невозможно;
3) отчетная документация, подаваемая в регулирующие органы, которая требует полной прослеживаемости параметров;
4) экстраполяция и/или применение модели за пределами диапазона ее обучения (например, при новых геологических условиях или других схемах нагружения) в случае отсутствия встроенных в модель знаний о физических законах;
5) критически важные для безопасности решения в режиме реального времени, если границы неопределенности недоступны или не отслеживаются.
Проблема 8. Учет этических и правовых аспектов
Модели искусственного интеллекта, которые основаны исключительно на данных, особенно подвержены непреднамеренному воспроизведению искажений, которые присутствовали в обучающих данных. Также возможно, что ключевым вопросом в будущих судебных разбирательствах станет тема ответственности и подотчетности, что сыграет важную роль в формировании правового регулирования применения ИИ в геотехнике. Кажется крайне важным, чтобы геотехническое сообщество быстро и проактивно включилось в дискуссии по этическим аспектам, связанным с использованием технологий ИИ в преподавании, научных исследованиях и промышленной практике в отрасли.
Прежде всего следует отметить, что применение искусственного интеллекта в геотехнике в обозримом будущем будет подразумевать участие человека в цикле принятия решений, то есть ИИ будет использоваться как инструмент, а не как полностью автономный агент.
Тем не менее потребуются руководящие принципы, определяющие ответственные подходы к применению искусственного интеллекта. Возможно также, что использование ИИ потребует значительно большей прозрачности, чтобы обеспечить интерпретируемость (объяснимость) прогнозов и удовлетворительный уровень подотчетности. Развивающееся правовое регулирование в этом направлении, вероятно, приведет к разработке нормативно-правовых документов и методических руководств, которые позволят сбалансировать технологические достижения с этическими соображениями.
—
Продолжение следует